Data Type View
Visions views data types through the lens of logical and physical data types.
This view can help guide our intuition around:
how types relate
how operations on types are performed
storage efficiency
the relations to Pandas’, Numpy’s and Python’s data models
It is limited with respect to:
intuitive understanding of membership constraints (see the nested set view).
the exact implementation (see the engineering view).
Concepts
When we refer to a data type or shortly type in visions, we mean abstract data type (ADT). An ADT is used by the user to abstract from data to solve subsequent tasks. When a data type isn’t abstract, we refer to it as a physical data type, which is concerned with storage of the data. The ADT internally represents the data in one or more physical data types. This abstraction is a powerful tool to the user.
For example, the data type integer can be stored as int64, int32, int16, int8, uint64 etc.
properties of AdT: expressiveness, low overhead complexity
Physical types
Logical types
Type detection
Type inference
Casting, coercion, conversion
Comparing with pandas
There are multiple problems when working with pandas for data analysis:
Missing values are handled inconsistently (int, bool, object)
Strings are stored as objects
Pandas’ functionality to create abstract data types is ExtensionsDType. It is expressive. Creating a new type has high overhead, as we need to define it from scratch for the lack of basic components.
Decoupling physical and logical types
Physical typesrepresent the actual, underlying representation of the data.Logical typesrepresent the abstracted understanding of that data.
To make this distinction more concrete we can imagine the sequence ['Apple', 'Orange', 'Pear'].
At a logical level these are of the type Fruit while under the hood each element is physically represented as String.
This separation is useful when we working with data that means something different to use, while being stored in the same physical data type. Another simple example is a set of URLs. While we might say all URLs are stored as strings, not every string is an URL. There are also operations that are only sensible on URLs and not on strings, such as extracting the url, domain, or protocol.
Problem with missing values
Pandas’ current data model is inconsistent with respect to missing values (i.e. NaN or None).
Adding missing values to integers and boolean results in upcasting to float and object respectively.
Implementing nullable integer and boolean logical types allow for more efficient storage which can be achieved
through an internal bitmap (see the engineering view for details).
Problem with strings
Pandas does not have a logical type “string”. Strings are stored as objects, which gives non-trivial overhead https://dev.pandas.io/pandas2/strings.html
Where the current models fail
The data models in Python, Numpy and Pandas are inconsistent and incomplete for logical storage of data types for analysis. Here, we try to understand the aspects relation to what are shortcomings of the current implementation and we want of the unified data model.
We first provide a motivating example why we need a new model. Secondly, we show what the data models of Python, Numpy and Pandas look like under the hood. The third part of this page introduces the concepts needed to combine them.
We are envisioning a one-to-one correspondence between each of the data models without loss. Types should be grouped together if they have the same analysis summary.
Motivating example: Nullable Boolean
Motivating example: Nullable Integer / Float
Motivating example: Objects
How do Python, Numpy and Pandas model data?
Python

Numpy
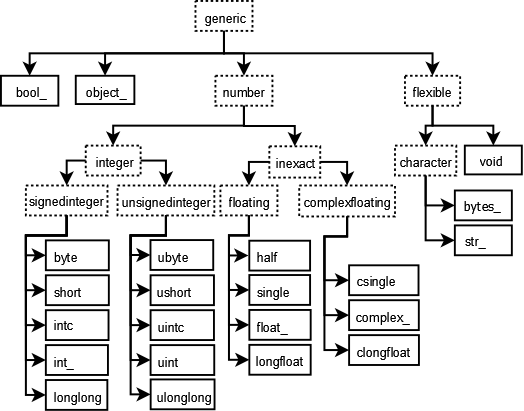
Pandas
Pandas Dtype |
Usage |
|---|---|
object |
Text or mixed |
int |
Integer |
float |
Floating point number |
complex |
Complex numbers |
bool |
Boolean value |
datetime[ns] |
Date and time value |
timedelta[ns] |
Difference between two datetimes |
category |
Categorical values |
Int |
Nullable integers |
Unifying, what do we need?
Custom dtypes.
References
We note that many of the problems visions attempts to solve, are discussed in the design documents for pandas 2.0 (2015-2016).